1. 项目介绍
1.1 客户名称
新鲜派餐饮集团(FreshGo Dining Group) 是国内领先的餐饮连锁品牌,拥有 300+ 门店,覆盖外卖、电商、线下餐饮等多渠道。集团希望以数据为核心驱动供应链与运营,具体目标包括:
- 提升供应链效率、减少食材浪费;
- 建立用户画像与个性化推荐体系,提升复购率与顾客粘性;
- 构建实时销售与运营监控平台,实现总部对全国门店的精细化管理。
1.2 客户挑战
- 数据源复杂且异构:应用程序产生的请求事件与业务数据(访问日志、订单、会员行为等)与第三方外卖平台数据并存,格式、字段口径与到达频次不一致,需统一接入、清洗与标准化。
- 实时性不足:既有日报/周报的离线分析无法支撑分钟级决策。
- 成本压力:历史数据量大、冷数据占比高,存储费用逐年攀升,同时需满足可查询与合规要求。
- 智能化能力薄弱:缺乏对需求预测、个性化推荐等场景的稳定数据底座与特征生产能力。
1.3 如何部署解决方案来应对挑战
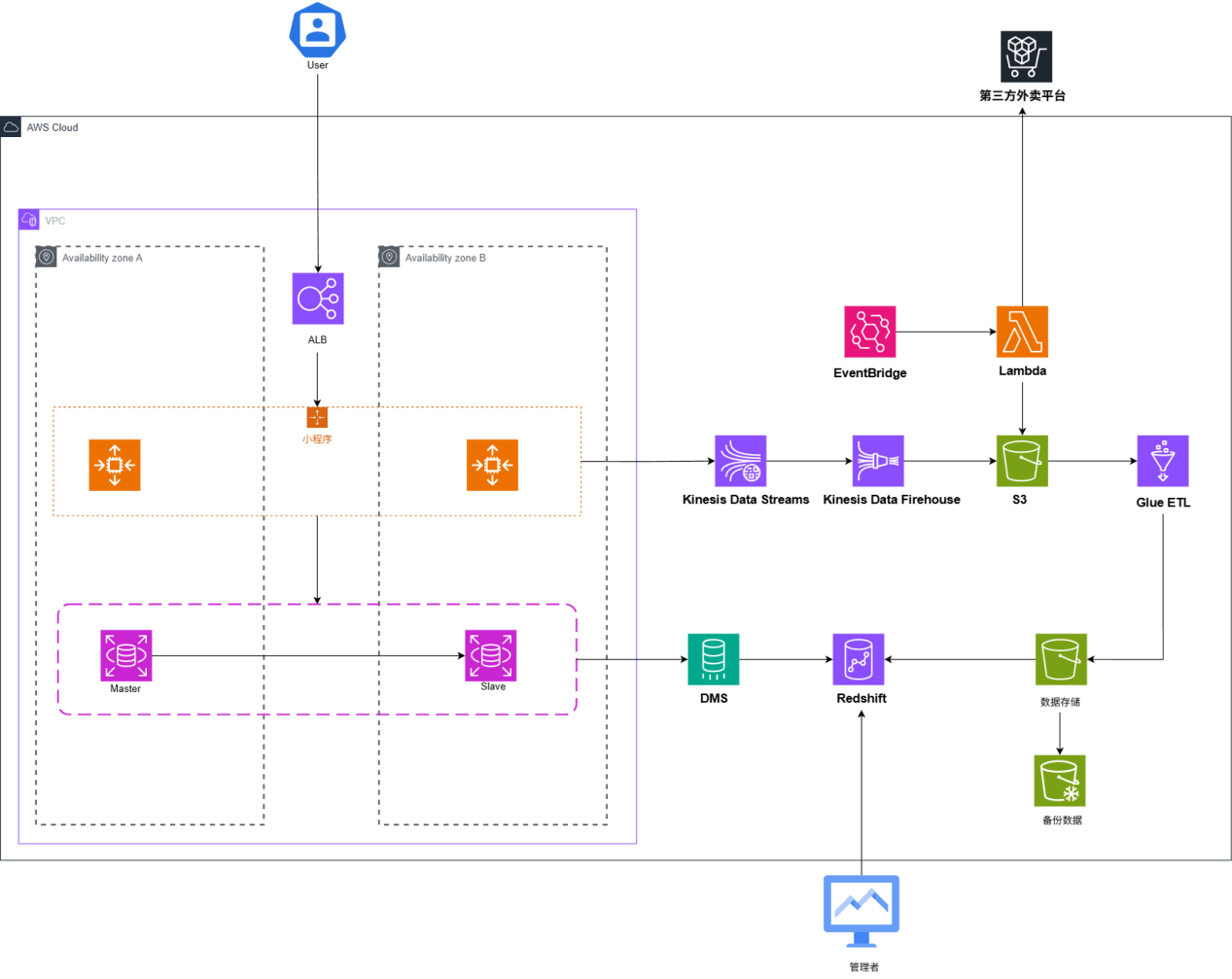
结合架构图,整体方案分为四个部分:
(1)用户访问与应用处理
- 终端用户(App/小程序/管理端)经 ALB 访问部署在公有子网后的 EC2 Auto Scaling Group。
- 后端服务跨多可用区部署于私有子网,弹性伸缩;业务产生的访问与订单日志写入日志代理。
(2)实时采集与传输
- Amazon Kinesis Data Streams 实时采集 App/小程序与门店侧产生的行为与订单事件。
- Kinesis Data Firehose 负责批量缓冲与压缩,将原始事件安全落地到 Amazon S3 原始区。
- 通过 Amazon EventBridge + AWS Lambda 对接第三方外卖平台回调/拉取接口,统一事件格式并写入 S3 或推送至 Kinesis。
(3)数据处理与仓库存储
- AWS Glue ETL(结合 Glue Data Catalog)自动读取 S3 原始数据,完成清洗、标准化与维度映射;产出写回 S3(明细层/数据集市层)。
- 生产库(如门店业务 MySQL 主从)通过 AWS DMS 进行 CDC 增量同步至 Amazon Redshift,构建统一数据仓库。
- 半结构化数据长期保存在 S3,通过 Redshift Spectrum 进行联邦查询与明细回溯。
- S3 配置分层与生命周期策略,将历史冷数据转入 S3 Glacier 以优化成本。
(4)数据分析与展示
- Amazon QuickSight 直连 Redshift 与 S3(Athena/Spectrum),为总部和区域经理提供实时运营看板、门店排行、库存预警与顾客洞察。
- 以统一数据资产支持用户画像与推荐特征计算,为后续规则/模型服务提供稳定输入。
1.4 结果
通过统一的数据湖与数据仓库架构,FreshGo 实现了从多源异构数据到"实时采集—治理—分析—洞察"的完整链路:
- 将分析延迟从 T+1 降至分钟级,支撑门店排班、缺货补货、异常订单等实时决策;
- 建立统一的会员与订单数据资产,支持用户画像与个性化推荐的特征生产;
- 冷热分层与 S3 Glacier 归档显著降低长期存储成本,同时保持合规与可查询能力;
- 通过 QuickSight 的总部看板与区域视图,实现对 300+ 门店的精细化运营与绩效对比;
- 数据平台对上屏蔽底层异构与变更,增强了未来向预测与智能化应用扩展的可持续性。
2. 架构设计
该方案的主要特点(按"两类数据源:应用程序事件/数据 + 第三方外卖平台数据"重述)
- 端到端链路清晰:围绕两类数据源构建"接入 → 采集/投递 → 存储/清洗 → 分析/可视化"的闭环,支撑实时与离线双场景。
- 高可用接入层:用户请求经公有子网中的 ALB 接入,转发至多可用区部署的 EC2 Auto Scaling Group,实现弹性伸缩与故障容错。
- 应用侧实时采集:后端服务将日志与用户行为事件写入 Kinesis Data Streams;由 Kinesis Data Firehose 进行批量缓冲与压缩,稳定投递到 Amazon S3。
- 外卖平台数据对接:通过 Amazon EventBridge + AWS Lambda 统一订阅/拉取第三方外卖平台数据(订单、评价、配送状态等),完成标准化后写入 S3(必要时也可推送至 Kinesis)。
- 统一数据湖:Amazon S3 作为数据湖承载原始区与清洗区,并按环境/域分层管理;配置独立备份路径与版本控制,便于回溯与审计。
- 治理与ETL:使用 AWS Glue ETL 周期性/准实时清洗 S3 原始数据,完成口径对齐、字段映射与分区压缩(如 Parquet),并登记到 Glue Data Catalog。
- 仓库与联邦分析:关键主题数据装载至 Amazon Redshift,支撑管理层集中查询;半结构化/历史明细保留在 S3,通过 Redshift Spectrum 查询。
- 可视化与自助分析:Amazon QuickSight 连接 Redshift/S3,提供仪表盘与报表;运营与业务人员可按门店/区域/渠道自助探索关键指标。
- 成本优化与归档:基于 S3 生命周期 将冷数据转入 S3 Glacier(或 S3 IA)分层存储,降低长期成本并保留可检索能力。
- 原生、可扩展、易运维:整体采用 AWS 原生组件,自动扩展与托管能力降低运维复杂度;配合 IAM/KMS、CloudWatch/CloudTrail 加固安全与可观测性,能够从容应对业务高并发与数据快速增长。